
【新智元導讀】李飛飛的 World Labs 首個「空間智慧」模型,剛剛誕生了!一張圖生成一個 3D 世界,網友驚呼:太瘋狂了,我們進入了下一輪革命,這就是視訊遊戲、電影的未來。
AI 生成 3D 世界成真了!
就在剛剛,AI 教母李飛飛創立的 World Labs 首次官宣「空間智慧」模型,一張圖,即可生成一個 3D 世界。
用李飛飛的話說,「無論怎樣理論化這個想法,都很難用語言描述一張照片或一句話生成 3D 場景的互動體驗。」
這是邁向空間智慧的第一步。
 互動傳送門:https://www.worldlabs.ai/blog#footnote1
互動傳送門:https://www.worldlabs.ai/blog#footnote1
所有場景都能在瀏覽器中實時渲染,還能實現可控的相機效果、可調節的模擬景深。

未來,遊戲 NPC 的虛擬世界可以隨意切換,都是分分鐘生成的事情。


英偉達高階研究科學家、李飛飛高徒 Jim Fan 總結道,「GenAI 正在創造越來越高維度的人類體驗快照。Stable Diffusion 是 2D 快照;Sora 是 2D+時間維度的快照;而 World Labs 是 3D、完全沉浸式的快照」。

今年 4 月,李飛飛被曝出開始自創業,專注於空間智慧,新公司私下融資直接晉升 10 億美元獨角獸。
直到 9 月,這家名為 World Lab 正式亮相,並在新一輪融資 2.3 億美金,得到了 AI 大牛 Geoffrey Hinton、Jeff Dean、谷歌前 CEO Eric Schmidt 等人的鼎力支援。
 World Labs 創始人團隊,左起依次為 Ben Mildenhall、Justin Johnson、Christoph Lassner 和李飛飛
World Labs 創始人團隊,左起依次為 Ben Mildenhall、Justin Johnson、Christoph Lassner 和李飛飛
如今醞釀半年多,空間智慧終見雛形。
網友們激動地表示,太瘋狂了,我們即將迎來一個像是 80 年代、90 年代那樣的革命。這將讓許多人實現他們的創意,有望降低開發成本,幫助工作室的新智慧財產權更大膽冒險。
這就是視訊遊戲、電影的未來。
VR 從此有了更多可能性。
探索一個新世界
不論是 Midjourney、FLUX,還是 Runway、DreamMachine,我們熟知的大多數 GenAI 工具僅能製作影像/視訊 2D 內容。
若是實現了在 3D 中生成,視訊的控制性、一致效能得到極大的改善。
這也就意味著,製作電影、遊戲、模擬器等其他物理世界的數位表現形式,將會發生翻天覆地的變化。
World Labs 成立開始的初衷便是,空間智慧的 AI 對世界進行建模,還能 3D 時空中物體/地點/互動進行推理。
這次,他們首次展示了這個 3D 生成的世界。
如下,是在瀏覽器中進行的實時渲染演示(注:AI 影像均由 FLUX 1.1 pro/Ideogram/Midjourney 生成)。
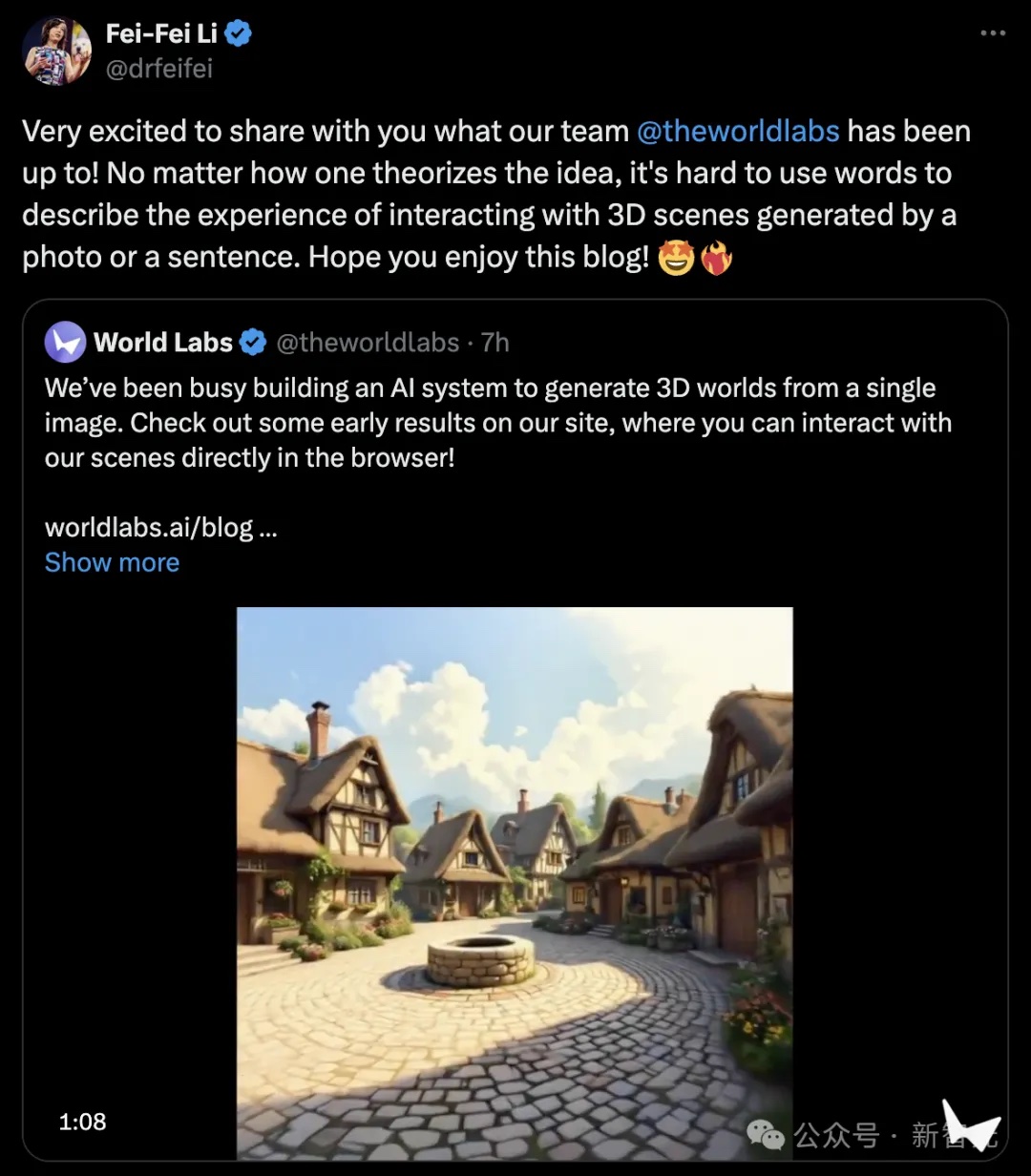
輸入一張 AI 生成的古色古香的村莊影像,然後就可以得到一個 3D 的世界。
 提示:這是一個古色古香的村莊,鵝卵石鋪就的街道,茅草屋頂的小木屋,中央廣場上有一口石井,周圍是花壇
提示:這是一個古色古香的村莊,鵝卵石鋪就的街道,茅草屋頂的小木屋,中央廣場上有一口石井,周圍是花壇

一座富麗堂皇的宮殿,AI 把光與影都展現得淋漓盡致。


一幅 AI 生成的摺紙類圖片,立刻活靈活現了起來。


又或者輸入一張博物館取景照片,誰又能想到這周圍是什麼樣子的呢?

AI 幫你設想出了一切,出入門,下一間相鄰的展館、展品。....

再比如這張實景圖,AI 也能想象出周圍的世界。


相機效果
你還可以體現不同相機效果,場景生成後,會使用虛擬相機在瀏覽器中進行實時渲染。
通過對這個相機的精準控制,便可以實現藝術攝影特效。
比如模擬不同的景深,讓只有在相機特定距離範圍內的物體保持清晰:

還可以模擬滑動變焦(dolly zoom),通過同時調整相機的位置和視場角來實現這一效果:

3D 特效
大多數生成式模型都是預測畫素的。而預測 3D 場景有很多好處:
- 場景永續性:一旦生成了一個世界,它就會穩定存在。即使你轉開視線後再次觀看,場景也不會在你看不見時發生變化。
- 實時控制:生成場景後,你可以在其中實時移動。你可以仔細觀察花朵的細節,或是探頭檢視角落後面有什麼。
- 幾何精確性:這個生成的世界遵循基本的 3D 幾何物理規則。它們具有真實的立體感和空間深度,與某些 AI 生成視訊的虛幻效果形成鮮明對比。
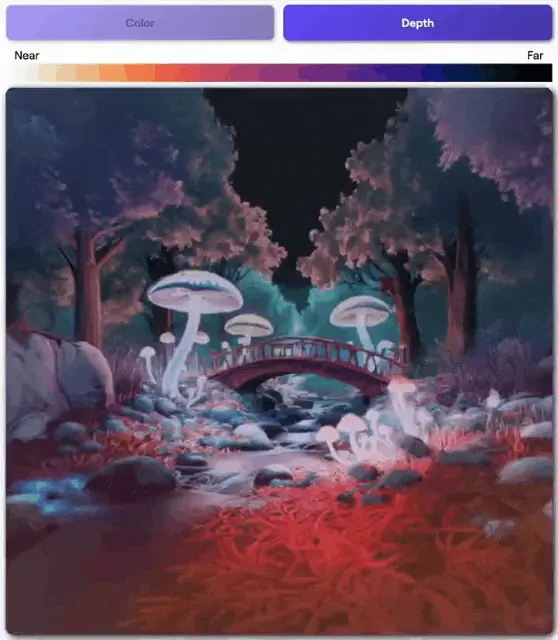
視覺化 3D 場景最簡單的方法是,就是使用深度圖(depth map)。在深度圖中,每個畫素都會根據其到相機的距離來著色:

我們不僅可以利用 3D 場景結構來建立互動特效:


還可以建立自動執行的動態效果,為場景注入生命力:
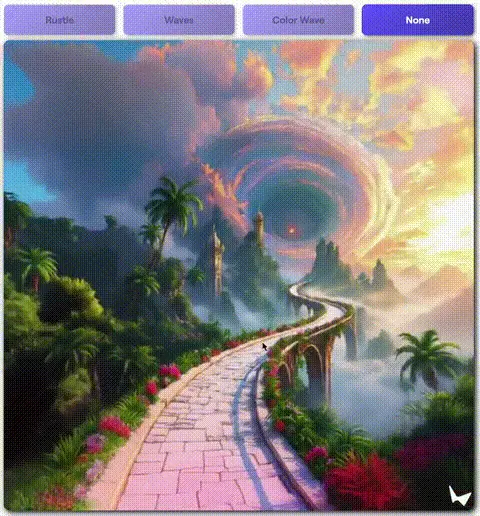
名畫中的 3D 世界也可實時互動了。
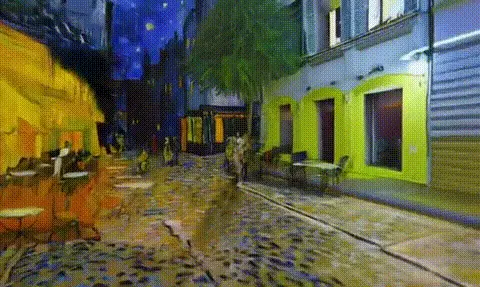
走進梵高的露天咖啡館
現在,我們可以以全新的方式,體驗標誌性的藝術作品了!
原畫中沒有任何東西,是由模型生成的。
下面,就讓我們走進從梵高、霍珀、修拉和康定斯基最喜歡的作品中生成的世界。

創意工作流
現在,3D 世界生成可以十分自然地和其他 AI 工具組合在一起,創作者們可以使用已知的工具,獲得無比絲滑的全新體驗了。
首先,可以通過使用文字到影像模型生成影像,來從文字建立世界。
不同的模型都有自己的不同風格,而空間智慧世界可以繼承這些風格。
下面就是使用不同的文字到影像模型生成同一場景的四個變體, 它們使用的都是相同的提示。
提示:一間充滿朝氣的動漫風格青少年臥室,床上鋪著五顏六色的毯子,書桌上雜亂地擺著一臺電腦,牆上貼滿了海報,各種運動器材隨意地散落在房間裡。一把吉他斜靠在牆邊,房間中央鋪著一塊帶有精美圖案的舒適地毯。窗外透進的陽光為整個房間營造出溫馨活力的青春氛圍。

現在,已經有一些創作者提前試用了。
比如 Eric Solorio 就使用這個模型,填補了自己創意工作流程中的空白,可以讓場景中的角色可以上陣,甚至還能指導攝像機精確移動。
Brittani Natail 則將 World Labs 技術與 Midjourney、Runway、Suno、ElevenLabs、Blender 和 CapCut 等工具相結合,在生成的世界中精心設計了攝像機路徑。
因此,得以在三部短片中喚起不同的情緒。
現在,候補名單已經開放了,話不多說了,趕快去申請吧。
空間智慧,計算機視覺下一個前沿
此前,李飛飛在一次活動中,首次詳細揭祕了何謂「空間智慧」:
視覺化為洞察,看見成為理解,理解導致行動。
她將人類智慧歸結為兩大智慧,一是語言智慧,另一個便是空間智慧。雖然語言智慧備受關注,但空間智慧將對 AI 產生重大的影響。

而在 4 月公開的 TED 演講中,李飛飛也分享了自己關於空間智慧的更多思考,同時預示著 World Labs 的目標所在。
她表示,「所有空間智慧的生物所具備的行動能力,是與生俱來的。因為,它能夠將感知與行動進行關聯」。
「如果想讓 AI 超越其自身當前的能力,我們需要的是,不僅僅能夠看到、會說話的 AI,而是一個可以行動的 AI」。

就連英偉達高階電腦科學家 Jim Fan 稱,「空間智慧,是計算機視覺和實體智慧體的下一個前沿」。
正如 World Labs 的官博所闡述的那樣,人類智慧包含了諸多方面。
語言智慧,可以讓我們通過語言與他們進行交流和聯絡。而其中最為基礎的便是——空間智慧,能夠讓我們理解,並與周圍世界進行互動。
此外,空間智慧具備了極強的創造力,可以將我們腦海中的畫面,在現實中呈現。
正是有了空間智慧,人類能夠推理、行動和發明。從簡單的沙堡到高聳的城市視覺化設計,都離不開它。

在接受彭博最新採訪中,李飛飛表示,人類的空間智慧,實際上經過了數百萬年的演化而來。
這是一種理解、推理、生成,甚至在一個 3D 世界中互動的能力。不論是你觀賞美麗的花朵,嘗試觸控蝴蝶,還是建造一座城市,所有這些皆是空間智慧的一部分。
不僅是人類,動物身上也可以看到這一點。

那麼,如何讓計算機也能具備空間智慧的能力呢?其實我們已經取得了巨大的進步,過去十年 AI 領域的發展相當振奮人心。
一句提示,AI 生成影像、視訊,真知還能講述故事。這些模型已經以全新的方式,重塑人類的工作和生活方式。
而我們僅是看到了 GenAI 革命前夜的第一章。
下一步,如何超越?
需要將這些能力,如何帶到 3D 領域。因為現實世界,就是 3D 的,同時人類空間智慧是建立在非常「原生」的理解和操作 3D 的能力之上的。

如今,單個影像生成 3D 世界模型,讓我們對空間智慧有了初步的理解。
參考資料: